44 class labels in data mining
What is Data Classification? A Data Classification ... For the purposes of data security, data classification is a useful tactic that facilitates proper security responses based on the type of data being retrieved, transmitted, or copied. Types of Data Classification. Data classification often involves a multitude of tags and labels that define the type of data, its confidentiality, and its integrity. Types Of Machine Learning: Supervised Vs Unsupervised Learning When new data is fed to the model, it will predict the outcome as a class label to which the input belongs. If the class label is not present, then a new class will be generated. While undergoing the process of discovering patterns in the data, the model adjusts its parameters by itself hence it is also called self-organizing.
Top 50 Data Mining Interview Questions & Answers ... Classification is the processing of finding a set of models (or functions) that describe and distinguish data classes or concepts, for the purpose of being able to use the model to predict the class of objects whose class label is unknown. Classification can be used for predicting the class label of data items.

Class labels in data mining
What is Label Encoding in Python | Great Learning In label encoding in Python, we replace the categorical value with a numeric value between 0 and the number of classes minus 1. If the categorical variable value contains 5 distinct classes, we use (0, 1, 2, 3, and 4). To understand label encoding with an example, let us take COVID-19 cases in India across states. Decision Tree Algorithm Examples in Data Mining The algorithm starts with a training dataset with class labels that are portioned into smaller subsets as the tree is being constructed. #1) Initially, there are three parameters i.e. attribute list, attribute selection method and data partition. The attribute list describes the attributes of the training set tuples. Hello! I am PAMI. A new Pattern Mining Python library for ... These techniques can be broadly classified into four types: Pattern mining — aims to find hidden patterns in the data Clustering — aims to group the data such that objects within a group have high intra-class similarly and low inter-class similarity. Classification — aims to find an appropriate class label for a test instance from a learnt model
Class labels in data mining. Data Mining Functionalities - An Overview Numeric Predictions - Predict any missing or unknown element in a data set. Class Predictions - Predict the class label using a previously built class model. Outlier Analysis. If we are unable to group any data in any class, we use the outlier analysis technique. Outlier analysis helps to learn about data quality. Classification in Data Mining Explained: Types ... Every leaf node in a decision tree holds a class label. You can split the data into different classes according to the decision tree. It would predict which classes a new data point would belong to according to the created decision tree. Its prediction boundaries are vertical and horizontal lines. 4. Random forest CAP 6673: Data Mining and Machine Learning The prescribed text book for this course is Data Mining and Machine Learning by Frank and Witten Syllabus Syllabus Data Sets The data sets are from a project labeled as CCCS. We will use two datasets: Fit Data set to fit the models Test Data set to evaluate the performance of the selected model on fresh (unseen) data. Top 20 Data Labeling Tools: In-depth Guide in 2022 Top 20 Data Labeling Tools: In-depth Guide in 2022. For performing data labeling, companies need a data labeling tool. There are different data labeling tools, each with its own advantages and disadvantages. In this article, we classify them to help companies choose the most suitable one.
The distance-based algorithms in data mining | by Nadeem ... The distance-based algorithms in data mining. The algorithms are used to measure the distance between each text and to calculate the score. ... (mode of the class label or mean of the real value ... Data Mining Techniques: Algorithm, Methods & Top Data ... #1) Frequent Pattern Mining/Association Analysis #2) Correlation Analysis #3) Classification #4) Decision Tree Induction #5) Bayes Classification #6) Clustering Analysis #7) Outlier Detection #8) Sequential Patterns #9) Regression Analysis Top Data Mining Algorithms Data Extraction Methods Top Data Mining Tools #1) RapidMiner #2) Orange #3) KEEL WEKA Datasets, Classifier And J48 Algorithm For Decision Tree The class label in this dataset is either good or bad. There are 700 instances of good (marked in blue) and 300 instances of bad (marked in red). For the label < 0, the instances for good or bad are almost the same in number. For label, 0<= X<200, the instances with decision good are more than instances with bad. Data Mining Techniques - GeeksforGeeks In general, the class labels do not exist in the training data simply because they are not known to begin with. Clustering can be used to generate these labels. The objects are clustered based on the principle of maximizing the intra-class similarity and minimizing the interclass similarity.
Implementing Naive Bayes Classification using Python Naive Bayes is a statistical classification technique based on the Bayes Theorem and one of the simplest Supervised Learning algorithms. The Naive Bayes classifier is a quick, accurate, and trustworthy method, especially on large datasets. This article will discuss the theory of Naive Bayes classification and its implementation using Python. Classification in Machine Learning: What it is and ... It is given by dividing the number of correctly classified data points by the total number of classified data points for that class label. Where : TP = True Positives, when our model correctly classifies the data point to the class it belongs to. FP = False Positives, when the model falsely classifies the data point. ML | Label Encoding of datasets in Python - GeeksforGeeks where 0 is the label for tall, 1 is the label for medium, and 2 is a label for short height. We apply Label Encoding on iris dataset on the target column which is Species. It contains three species Iris-setosa, Iris-versicolor, Iris-virginica . Python3 # Import libraries import numpy as np import pandas as pd # Import dataset k-means clustering in Python [with example] Once the k-means clustering is completed successfully, the KMeans class will have the following important attributes to get the return values,. labels_: gives predicted class labels (cluster) for each data point cluster_centers_: Location of the centroids on each cluster.The data point in a cluster will be close to the centroid of that cluster. As we have two features and four clusters, we ...
CPPTRAJ Manual
prediction in data mining - yamanashiwinetaxi.com there are several major data mining techniques that have been developing and using in data mining projects recently including association, classification, clustering, prediction, sequential patterns, and decision tree. data classification and prediction for large databases, data classification is a two-step process.in the first step,a model is …

How do you learn labels with unsupervised learning ... The clustering assigns arbitrary categorical "labels" which can be further analyzed to discern whether they represent true, meaningful classes in your data. If you have a useful clustering, you can then use those labels in a supervised manner to train a classifier.

NLP - News classification :: Imad El Hanafi — Portfolio & Blog
Difference Between Classification and Prediction methods ... We use these two techniques to analyze the data, to explore more about unknown data. Classification: Classification is the process of finding a good model that describes the data classes or concepts, and the purpose of classification is to predict the class of objects whose class label is unknown.
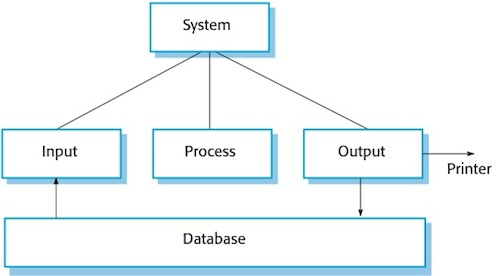
Computer Education: Data processing
How to classify ordered labels(ordinal data)? - Stack Exchange In classification problems one usually uses categorical variables. An example are One-hot vector, that have a 1 in the index of the corresponding label and 0 on the rest: label 3 -> [0,0,1,0,0,0,0,0,0,0] So if you transform your label to a one hot vector, you can now create a mathematical model.

PPT - Data Stream Mining PowerPoint Presentation, free download - ID:816505
Curse of Dimensionality — A "Curse" to Machine Learning ... Today, this phenomenon is observed in fields like machine learning, data analysis, data mining to name a few. An increase in the dimensions can in theory, add more information to the data thereby improving the quality of data but practically increases the noise and redundancy during its analysis.
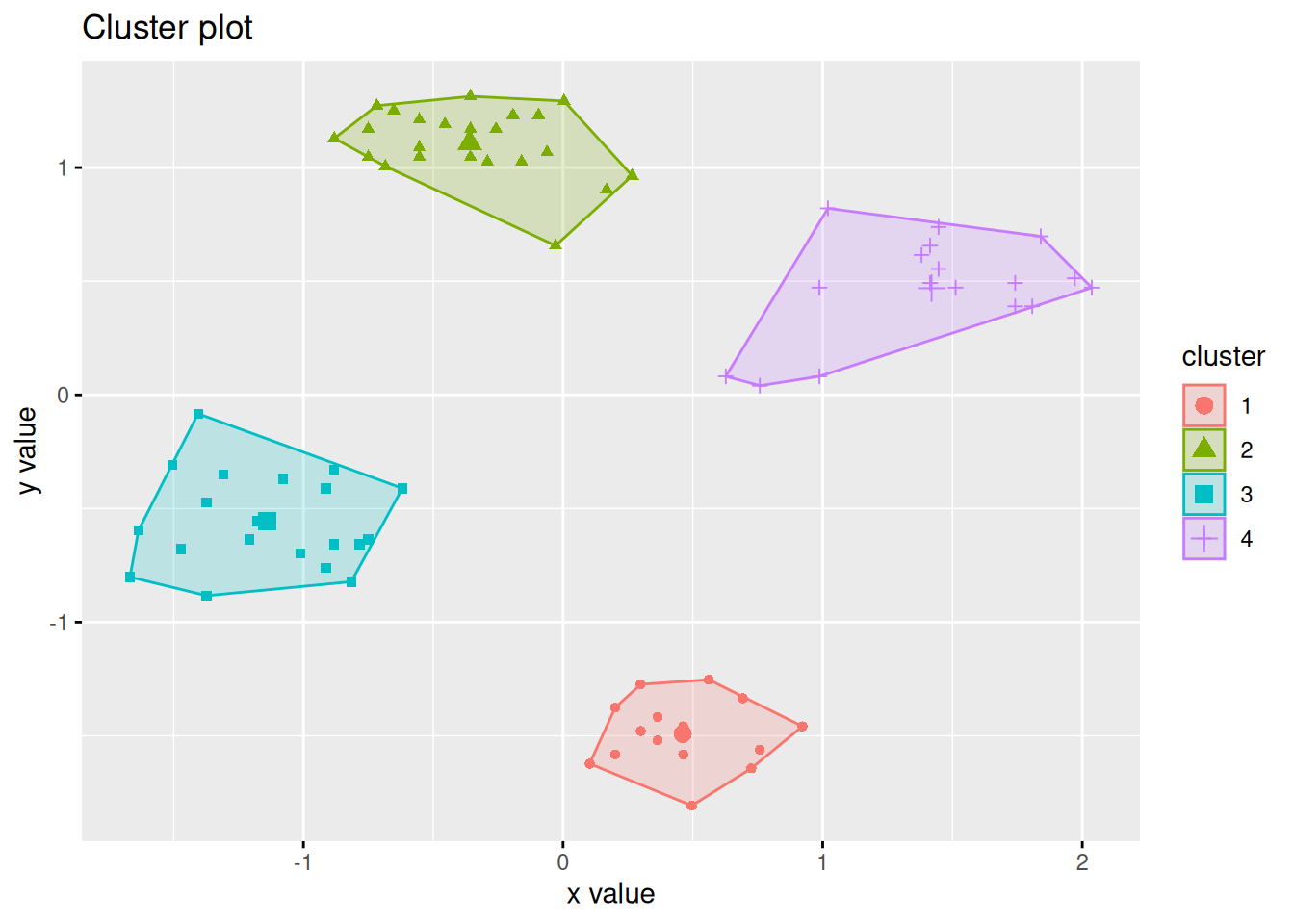
Chapter 7 Clustering Analysis | An R Companion for Introduction to Data Mining
WEKA Explorer: Visualization, Clustering, Association Rule ... #1) Open WEKA Explorer and click on Open File in the Preprocess tab. Choose dataset "vote.arff". #2) Go to the "Cluster" tab and click on the "Choose" button. Select the clustering method as "SimpleKMeans". #3) Choose Settings and then set the following fields: Distance function as Euclidian The number of clusters as 6.

What are the functionalities of data mining? There are various data mining functionalities which are as follows −. Data characterization − It is a summarization of the general characteristics of an object class of data. The data corresponding to the user-specified class is generally collected by a database query. The output of data characterization can be presented in multiple forms.

(PDF) DCDistance: A Supervised Text Document Feature extraction based on class labels
Basic Concept of Classification (Data Mining) - GeeksforGeeks Classification is the problem of identifying to which of a set of categories (subpopulations), a new observation belongs to, on the basis of a training set of data containing observations and whose categories membership is known. Example: Before starting any project, we need to check its feasibility.
Post a Comment for "44 class labels in data mining"